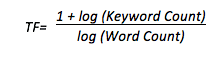As SEO professionals, it falls to us to track Google’s ever-shifting mood and the flow of the algorithm’s 200+ ranking factors, and then create action points from our findings. Over our many years in the business, if there is one thing we have discovered, it is this:
Content is indeed King.
Good content can make or break a website, drawing your customer in with relevant information or expelling them out into the cold. Interestingly, the content’s importance is criminally underappreciated by the modern SEO community. Many professionals in our industry are so focused on the numbers game that few surfaces long enough to address any lacking content. We reckon it’s time for that to change.
This is why we’re taking you through the basics of the TF-IDF content optimisation.
What Is TF-IDF?
TF-IDF (term frequency and inverse document frequency) measures how important a given keyword is on the assigned page by comparing it to a set of pages ranking for that given keyword. TF-IDF shows you semantically related terms that Google finds highly relevant to that keyword, making it more likely that your content will be interpreted referring to someone searching.
By comparing your page to highly ranked pages in the same category, TF-IDF downplays unimportant words and upscales words with significance.
For example, the page you want to optimise may be about whiskey. Word articles like “the”, “and”, and “to” will be very common across all top pages in this topic because these words are present in pretty much everything. However, words like “single malt”, “Irish whiskey”, and “distillation process” are less common. Therefore, they jump out to Google as indications of content that’s highly relevant to the main topic—whiskey.
By including these relevant keywords in your content, you communicate your page’s quality to the search engine overlords. Therefore, Google is more likely to rank your content among the best. That’s what makes TF-IDF so invaluable.
The Nitty Gritty
TF-IDF is broken down into two parts: TF (term frequency) and IDF (inverse document frequency).
Term Frequency is the number of times a keyword shows up on a page expressed in a normalised way. The equation to get term frequency uses a logarithm, a function used in mathematics to “normalise” data, so big differences can be expressed in small numeric shifts.
Using a logarithm is a huge part of why TF-IDF works so well. It minimises something called “noise” in the data, which is the fuzzy bits, outliers, and irrelevant data that can throw off a given measurement, and instead gives us a clear numeric value with which we can assess a term’s frequency.
Inverse Document Frequency is the ratio of all documents in the assessing body to the documents containing your given keyword. If the number of documents with the keyword is smaller, the IDF figure will be larger, whereas if a larger number of documents contain the keyword, the IDF figure will be smaller. When we multiply the IDF with TF, we’ll end up with a figure that reflects the rarity of your given keyword. A large TF-IDF indicates a rarer keyword, while a small TF-IDF indicates a common one.
Why Use TF-IDF for Content Optimisation?

Keyword research for content optimisation purposes is usually done from a “density” point of view. That is: what is the ideal number of times for my target keyword to show up in my content so Google will sit up and take notice?
SEO professionals created this approach in an attempt to understand Google’s view on how keywords indicate relevancy, and we still use keyword density to this day! However, the density of a keyword doesn’t tell the whole story.
From what the professional SEO community knows, Google uses contextual hints to determine how relevant a page is to a searcher’s query. This is what we call “semantic SEO”. Semantic SEO is the whole reason why the page with the highest keyword density doesn’t rank at the top of the SERP. Google needs a little more proof that your content is about what you say it’s about, and weeds out websites that stuff their keywords needlessly to try and game the system.
Google’s Focus on Semantic SEO
Patents assigned to Google show that they’ve actually never used keyword density as a measure of page relevance because it’s just too “noisy”. The data is too unpredictable and can’t be refined well enough to use as a measure across something as expansive as the entire Internet, so Google has been using TF-IDF as their measure for a very long time.
While the language in the patent itself is somewhat difficult to wade through, the long and short of it speaks to a TF-IDF approach to document ranking. By identifying term relationships within the document as well as between other documents, Google can use this information to establish a hierarchy and rank pages accordingly. Furthermore, by avoiding noisy data and using existing content to establish what relevant content looks like, Google has created a ranking system geared towards the user, not the creator. That’s why we all have to work a little bit harder.
Since Google uses TF-IDF, incorporating it into your own SEO practice is the best way to make sure your site reflects Google’s user-oriented expectations. But don’t be too fast to throw your keyword density data out with the bathwater! These tools are still helpful for identifying if you’re keyword stuffing, which is a big no-no in Google’s eyes.
Need an expert to handle your SEO?
Pure SEO is New Zealand’s most awarded digital marketing agency, and we’re geared towards optimising your website to be the best it possibly can be! From semantic SEO to SEM, put yourself on the digital map alongside your competitors with the Kiwi SEO experts.